InstructPix2Pix: Learning to Follow Image Editing Instructions
We propose a method for editing images from human instructions: given an input image and a written instruction that tells the model what to do, our model follows these instructions to edit the image. To obtain training data for this problem, we combine the knowledge of two large pretrained models -- a language model (GPT-3) and a text-to-image model (Stable Diffusion) -- to generate a large dataset of image editing examples. Our conditional diffusion model, InstructPix2Pix, is trained on our generated data, and generalizes to real images and user-written instructions at inference time. Since it performs edits in the forward pass and does not require per example fine-tuning or inversion, our model edits images quickly, in a matter of seconds. We show compelling editing results for a diverse collection of input images and written instructions.
Problem:: 단순 지시문(Instruction) 기반 이미지 편집을 위한 대규모 데이터셋이 부재함 / 기존 편집 방식들은 전체 설명, 마스크, 추가 예시 등 번거로운 입력을 요구함
Solution:: GPT-3와 Stable Diffusion을 결합하여 (이미지, 지시문, 편집된 이미지) 쌍으로 구성된 데이터셋을 자동으로 생성함 / 생성된 데이터셋으로 InstructPix2Pix라는 조건부 Diffusion 모델을 학습시킴
Novelty:: 기존의 거대 모델들을 활용해 새로운 태스크에 대한 학습 데이터셋을 생성하는 방법론 그 자체 / 단순 '설명'이 아닌 '지시문'을 따르도록 모델을 학습시킨 점 / 이미지-텍스트 두 조건에 대한 Classifier-Free Guidance Scale(sI, sT)을 분리하여 편집 과정을 제어한 기법
Note:: 원하는 텍스트 자체에 대한 설명문보다 변환 지시문을 생성한 접근이 신선함 / 논문에 텍스트가 이렇게 없다니..
Summary
Motivation
- 기존 Text 기반 이미지 편집 방식은 이미지 전체 설명을 요구하거나, 사용자 Mask, 추가 예제, 이미지별 Fine-Tuning 등이 필요해 번거로운 단점이 있었음.
- 이걸 해결하려고, 사람이 쓰는 자연어 '지시문'을 직접 이해하고 따르는 편집 모델을q 만들고자 함. 예를 들어 "해바라기를 장미로 바꿔줘" 같은 직접적인 명령으로 편집하는 게 목표임.
- 근데 이런 Instruction 기반 편집을 학습시킬 (원본 이미지, 지시문, 편집된 이미지) 쌍으로 된 대규모 데이터셋이 없음.
- 그래서 이 논문에서는 이미 있는 거대 모델 두 개(GPT-3, Stable Diffusion)의 지식을 써서 필요한 학습 데이터셋을 자동으로 생성하는 방식을 제안함.
Method

방법론은 크게 두 단계임: (1) 데이터셋 생성, (2) 생성된 데이터셋으로 조건부 Diffusion 모델 학습.
Training Data Generation
- Paired Caption Generation
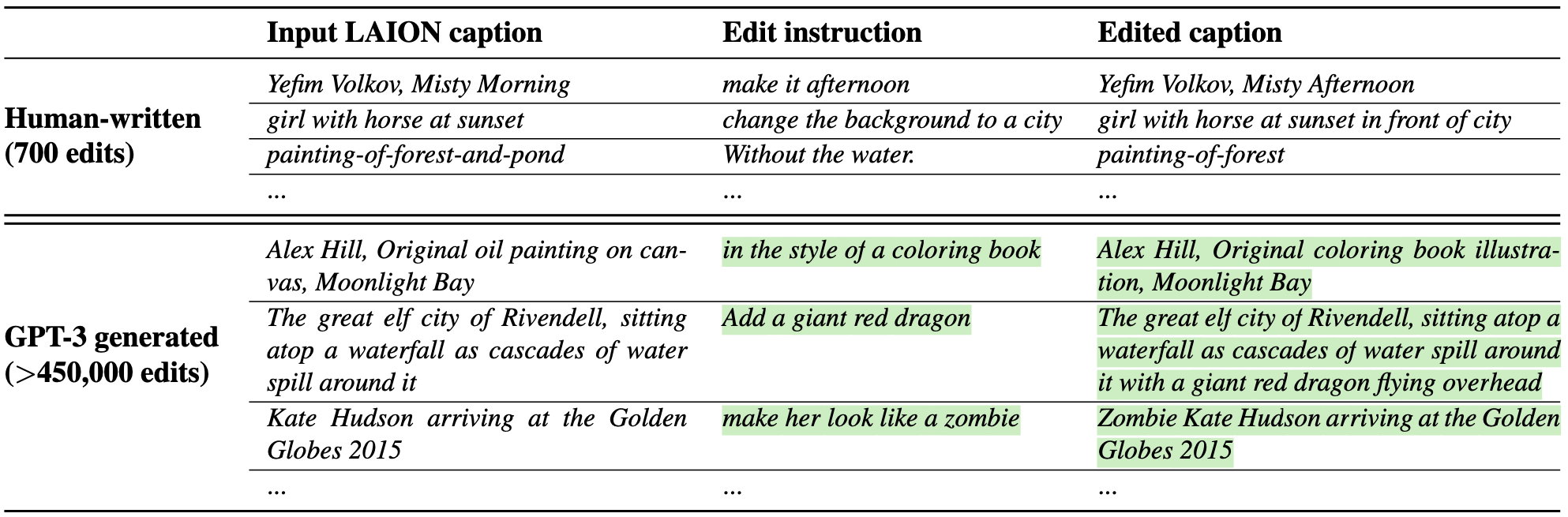
- 일단 사람이 700개의 (Input Caption, Edit Instruction, Output Caption) 데이터셋을 직접 만듦.
- 이걸로 GPT-3를 Fine-Tuning해서 LAION 데이터셋 캡션을 입력으로 45만 개 이상의 (Input Caption, Instruction, Output Caption) 삼중항(Triplet)을 자동으로 생성함.
- Paired Image Generation

- 생성된 캡션 쌍으로 이미지 쌍을 만들기 위해 Stable Diffusion과 Prompt-to-Prompt 기법을 같이 씀. Prompt-to-Prompt는 비슷한 프롬프트 간 이미지 구조 일관성을 유지해 줌.
- 최종적으로 만들어진 여러 이미지 쌍 중 품질 좋은 걸 고르려고 CLIP 기반의 Directional Similarity Metric으로 데이터를 필터링함 → 캡션 변화랑 이미지 변화 방향이 일치하는지 측정해서 데이터 품질을 높여줌.
Instruction-following Diffusion Model
- 모델 구조는 사전 학습된 Stable Diffusion 기반의 조건부 Latent Diffusion 모델임.
- 기존 Text 조건부 입력(
)에 더해서 원본 이미지를 조건부 입력( )으로 같이 쓰려고 U-Net 첫 레이어에 입력 채널을 추가함. - 이 논문의 핵심 아이디어 중 하나는 두 조건(이미지, 텍스트)에 대한 Classifier-Free Guidance를 별도로 제어하는 것임.
- Image-Guidance Scale (
) 과 Text-Guidance Scale ( ) 두 개를 도입함. 는 결과물이 원본 이미지와 얼마나 비슷할지, 는 편집 지시문을 얼마나 잘 따를지 제어함.

- Image-Guidance Scale (
- 수식은 아래와 같음:
Method 검증
- 정성적 평가 (Qualitative Evaluation)
- 실제 사진, 유명 예술 작품에 대해 다양한 편집(객체 교체, 스타일 변경 등)을 성공적으로 수행함.
- 정량적 비교 (Quantitative Comparison)
- 실험 제목: Baseline 모델과 성능 비교
- 실험 진행 방법: SDEdit을 비교군으로 두고, Y축은 CLIP Image Similarity(원본 유사도), X축은 CLIP Text-Image Direction Similarity(편집 일관성)로 성능을 비교함.
- 비교군: Ours, SDEdit (Instruction), SDEdit (Caption)
- 정량적 성능:
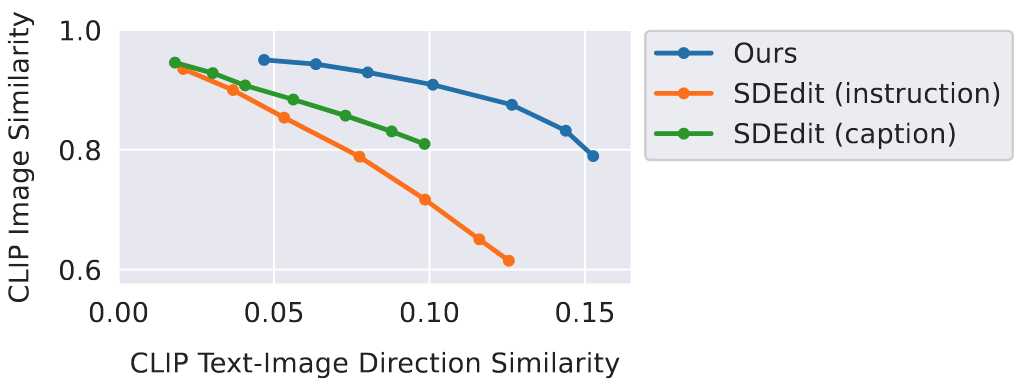
- 동일한 편집 일관성(X축)에서 InstructPix2Pix (Ours)가 SDEdit보다 원본 이미지 유사도(Y축)가 월등히 높음.
- 통찰: 제안 모델이 원본 이미지 구조와 내용을 더 잘 보존하면서 원하는 편집을 수행할 수 있다는 걸 의미함.
- 실험 제목: Baseline 모델과 성능 비교
- Ablation Study: 데이터셋 크기 및 필터링 효과
- 실험 제목: 데이터셋 구성에 따른 성능 변화 분석
- 실험 진행 방법: 전체 데이터의 1%, 10%만 쓴 모델, CLIP 필터링을 안 쓴 데이터로 학습한 모델의 성능을 비교함.
- 정량적 성능:
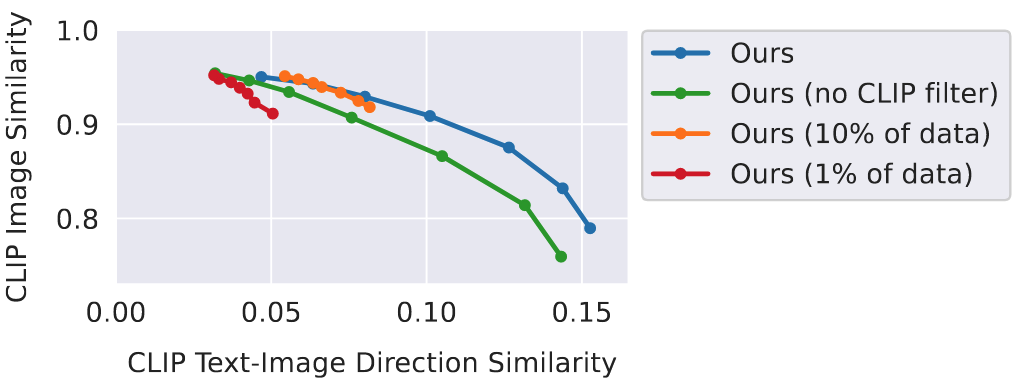
- 데이터셋 크기를 줄이니 편집 일관성이 크게 떨어짐.
- CLIP 필터링을 빼니 전반적으로 원본 이미지 유사도가 감소함.
- 통찰:
- 대규모 데이터셋이 모델의 편집 능력에 결정적임.
- CLIP 기반 데이터 필터링이 고품질 데이터 생성과 모델 성능 향상에 기여함.
- 실험 제목: 데이터셋 구성에 따른 성능 변화 분석