MulT: An End-to-End Multitask Learning Transformer
We propose an end-to-end Multitask Learning Transformer framework, named MulT, to simultaneously learn multiple high-level vision tasks, including depth estimation, semantic segmentation, reshading, surface normal estimation, 2D keypoint detection, and edge detection. Based on the Swin transformer model, our framework encodes the input image into a shared representation and makes predictions for each vision task using task-specific transformer-based decoder heads. At the heart of our approach is a shared attention mechanism modeling the dependencies across the tasks. We evaluate our model on several multitask benchmarks, showing that our MulT framework outperforms both the state-of-the art multitask convolutional neural network models and all the respective single task transformer models. Our experiments further highlight the benefits of sharing attention across all the tasks, and demonstrate that our MulT model is robust and generalizes well to new domains. Our project website is at https://ivrl.github.io/MulT/.
Problem:: 기존 Transformer 모델들의 Single Task 중심 연구 한계 / 다양한 Vision Task (2D, 3D, Semantic) 통합 및 Task 간 상호 의존성 모델링 필요성 / 기존 Multitask 접근법의 Task 의존성 명시적 인코딩 부족
Solution:: End-to-End Multitask Learning Transformer 프레임워크 MulT 제안 / Swin Transformer 기반 공유 Encoder를 통한 공통 Representation 학습 / Task별 Transformer Decoder Head를 통한 개별 Task 예측 수행 / Shared Attention Mechanism을 통한 Task 간 의존성 모델링
Novelty:: 다수의 고수준 Vision Task (Depth, Segmentation, Normal, Reshading, Keypoints, Edges) 동시 처리를 위한 End-to-End Multitask Transformer 아키텍처 / 참조 Task의 Q/K Projection을 활용하여 생성된 Attention Map을 모든 Task의 Value에 적용하는 Shared Attention Mechanism 도입 / Task 간 Attention 공유를 통해 각 Vision Task 성능 향상 입증
Note:: 말만 번지르르하고 공개한 코드와 논문 내용이 일치하지 않음. Encoder 모듈과 Decoder 모듈은 크게 새로운게 없는데 길게 설명하고 정작 중요한 Shared Attention의 설명은 모호한 부분이 많음. 참조 태스크를 실험적으로 선정했다고 했으나 구현된 코드에는 단순히 모든 디코더에 대해 공통적으로 q,k를 계산할 뿐이었음. Shared Attention의 유용성에 대한 정량적 성능 비교가 없고 오직 정성적 비교 밖에 존재하지 않음. 따라서 Swin이 Multi-Task Learning에 효과적이어서 성능 향상이 일어났는지, Shared Attention을 사용해서 일어났는지 알 수가 없음.
Summary
Motivation
- 트랜스포머는 이미지 분류, 객체 탐지, Panoptic Segmentation 등 다양한 도메인에서 성공적으로 적용되고 있으나, 대부분의 연구는 단일 작업에 초점을 맞춤
- 일부 연구들이 멀티태스크 학습에 트랜스포머를 적용했지만, 작업 간 의존성을 명시적으로 모델링하는 접근법이 부족함
- 본 연구의 목표는 2D, 3D, 의미론적 영역을 포괄하는 다양한 비전 작업들을 하나의 모델에서 효과적으로 연결하는 것
- 핵심 연구 질문:
- 트랜스포머가 작업 간 공동 학습을 통해 단일 작업 트랜스포머보다 성능을 향상시킬 수 있는가?
- 트랜스포머 기반 프레임워크에서 작업 간 의존성을 명시적으로 인코딩할 수 있는가?
- 멀티태스크 트랜스포머가 새로운 도메인에 잘 일반화될 수 있는가?
Method
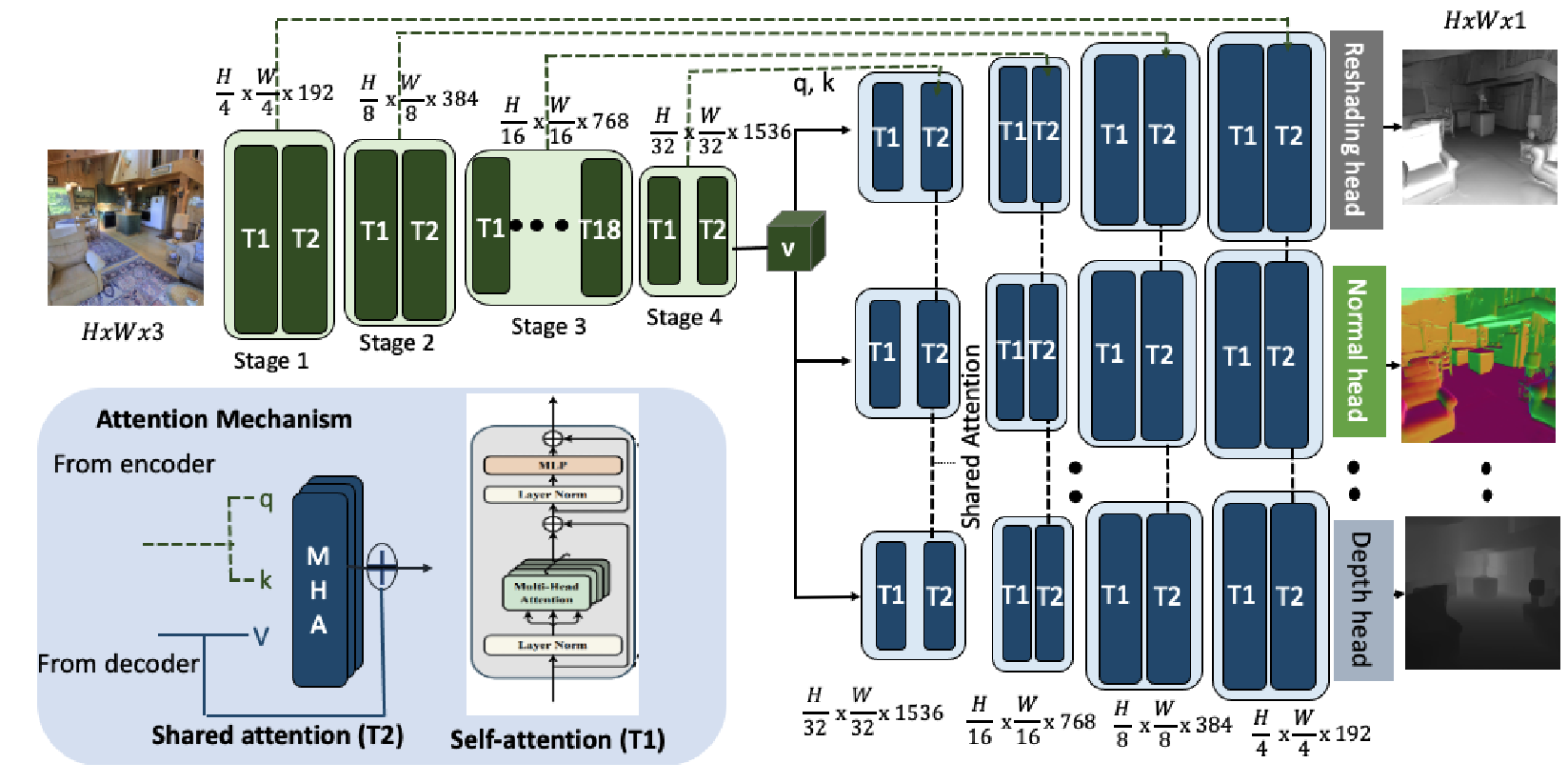
- Swin 트랜스포머 기반 인코더-디코더 구조 채택
- Encoder: 입력 이미지를 모든 작업이 공유하는 잠재 표현으로 변환
- Swin-L 아키텍처를 기반으로 피라미달 방식으로 점진적으로 해상도가 감소하고 채널 차원이 증가하는 구조
- 각 스테이지는 Patch Embedding(공간 해상도 감소 및 채널 차원 증가)과 트랜스포머 블록 시퀀스로 구성
- Window-based Self-attention: 큰 해상도에서 계산 효율성을 위해 토큰을 겹치지 않는 윈도우(7×7)로 분할
- 일반 윈도우 분할과 이동 윈도우 분할을 번갈아 사용하여 장거리 상호작용 가능하게 함
- Decoder: 트랜스포머 기반 디코더와 작업별 헤드를 사용해 각 비전 작업의 최종 예측 생성
- 4단계로 구성, 각 단계는 2개의 트랜스포머 블록 포함(총 8개)
- Upsampling: 단계 사이에 공간 해상도 2배 증가, 채널 차원 절반으로 감소
- Encoder-Decoder Skip Connection: 모래시계 구조로 다양한 수준의 의미론적 정보 활용
- 모든 작업이 동일한 인코더를 공유하고, 아키텍처는 같지만 파라미터가 다른 작업별 디코더 사용
- Head: 트랜스포머 디코더 출력을 각 비전 작업의 최종 예측으로 변환하는 간단한 레이어
- 가중합 기반 작업별 Loss 함수로 네트워크 공동 학습
- 각 작업에 적합한 Loss 함수 사용:
- Semantic Segmentation: Cross-entropy
- Depth: Rotate loss
- Surface Normal, 2D Keypoint, 2D Edge, Reshading: L1 loss
- 작업 간 의존성을 모델링하는 Shared Attention Mechanism
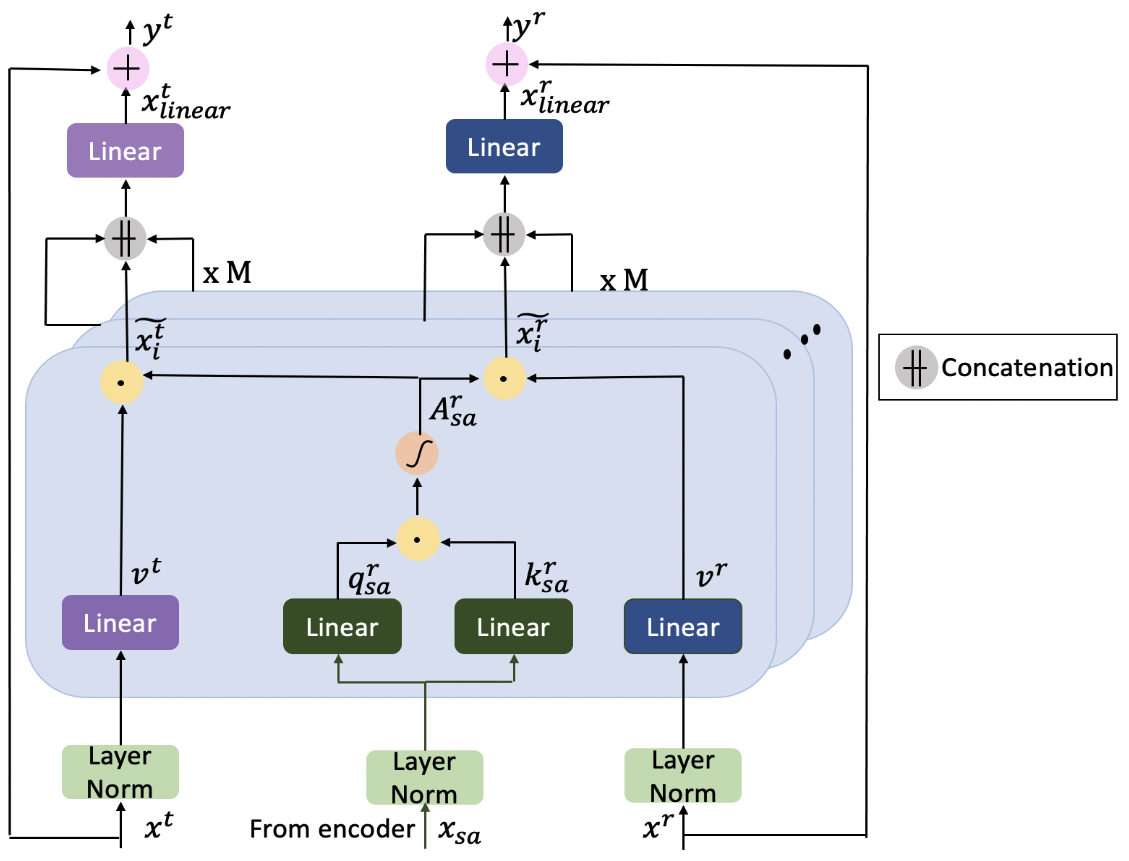
- 인코더에서 얻은 Query와 Key 벡터를 기준 작업(Surface Normal)에서 가져오고, 디코더에서 생성된 작업별 Value 벡터를 결합 → 코드 구현을 보면 기준 작업에서 가져오지 않음. 그냥 각 디코더에서 공통 q, k를 사용
- Shared Attention 계산:
- 모든 작업
에 대해 계산 - 이를 통해 작업 간 정보 공유가 가능하며 각 작업의 성능을 향상시킴 → 작업 간 정보 공유? 그냥 공통 q, k 사용이 끝
Method 검증
데이터셋 및 실험 설정
- 사용 데이터셋:
- Taskonomy: 주요 학습 데이터셋, 4백만 실내 이미지와 다중 작업 주석
- Replica: 고해상도 3D Ground Truth로 세밀한 평가 가능
- NYU: 464개 다양한 실내 장면의 1449 이미지
- CocoDoom: Doom 비디오 게임의 합성 이미지로 학습 분포 외 성능 평가
- 학습 설정: 배치 크기 32, 32개 V100 GPU, 가중 Adam 최적화, 학습률 5e-5
페어와이즈 학습 결과
- 실험: 두 작업씩 쌍으로 학습하고 한 작업에서 테스트
- 결과: Surface Normal 태스크가 다른 비전 작업 성능 향상에 크게 기여
- Surface Normal + 2D Keypoint: Keypoint 성능 +91.2% 향상
- Surface Normal + 2D Edge: Edge 성능 +77.1% 향상
- 통찰: 작업 간 구조적 유사성이 성능 향상의 핵심 요소이며, CNN과 유사한 멀티태스크 친화성 패턴 발견
6-작업 통합 성능
- 실험: 6개 작업(Semantic Segmentation, Depth, Surface Normal, 2D Keypoint, 2D Edge, Reshading) 동시 학습
- 결과:
- 단일 작업 Swin 대비: 최대 +94.75%(2D Keypoint) 성능 향상
- 단일 작업 CNN 대비: 최대 +97.04%(2D Keypoint) 성능 향상
- 모든 멀티태스크 CNN 베이스라인보다 우수한 성능
- 통찰: 작업 수가 증가할수록 MulT 성능 향상(6작업 > 5작업 > 4작업), 작업 간 상호보완적 특성이 효과적으로 활용됨
도메인 일반화 및 적응 능력
- 실험: 학습되지 않은 새로운 도메인(Replica, NYU, CocoDoom)에 적용
- 결과:
- Replica: Depth +10.1%, Normal +8.59%, Reshading +19.6% 성능 향상
- NYU: Segmentation +15.7%, Depth +10.4% 성능 향상
- CocoDoom: 평균 오류 39.3% 감소
- 통찰: Shared Attention Mechanism이 새로운 도메인에 대한 일반화 능력을 향상시킴
결론 및 한계점
- 주요 성과:
- 단일 네트워크로 여러 비전 작업 동시 처리 가능
- 단일 작업 모델 및 CNN 기반 멀티태스크 모델 대비 성능 향상
- 새로운 도메인에 대한 우수한 일반화 능력
- 한계점:
- 데이터 의존성: 제한된 데이터에서는 성능이 저하될 수 있음
- 페어링된 학습 데이터 필요: 미래에는 레이블이 없거나 페어링되지 않은 데이터로 확장 필요
- 효율적인 어텐션 모델링: Local vs Global Attention 등의 추가 연구 필요