MTLoRA: Low-Rank Adaptation Approach for Efficient Multi-Task Learning
Adapting models pre-trained on large-scale datasets to a variety of downstream tasks is a common strategy in deep learning. Consequently, parameter-efficient fine-tuning methods have emerged as a promising way to adapt pretrained models to different tasks while training only a minimal number of parameters. While most of these methods are designed for single-task adaptation, parameter-efficient training in Multi-Task Learning (MTL) architectures is still unexplored. In this paper, we introduce MTLoRA, a novel framework for parameter-efficient training of MTL models. MTLoRA employs Task-Agnostic and Task-Specific LowRank Adaptation modules, which effectively disentangle the parameter space in MTL fine-tuning, thereby enabling the model to adeptly handle both task specialization and interaction within MTL contexts. We applied MTLoRA to hierarchical-transformer-based MTL architectures, adapting them to multiple downstream dense prediction tasks. Our extensive experiments on the PASCAL dataset show that MTLoRA achieves higher accuracy on downstream tasks compared to fully fine-tuning the MTL model while reducing the number of trainable parameters by 3.6×. Furthermore, MTLoRA establishes a Pareto-optimal trade-off between the number of trainable parameters and the accuracy of the downstream tasks, outperforming current stateof-the-art parameter-efficient training methods in both accuracy and efficiency. Our code is publicly available.
Problem:: LoRA는 효과적이지만 MTL에서 효과가 떨어짐 / 각 Task별로 새로운 LoRA를 도입하는 것은 연산량을 증가시킴
Solution:: MTL 시나리오에 맞는 Task Specific, Task Agnostic LoRA 모듈 제안 / 각 Encoder Stage 마지막에만 Task 별 LoRA를 도입해 연산량 증가 최소화
Novelty:: MTL 시나리오에서 LoRA를 처음으로 사용
Note:: MultiLoRA 논문이 LoRA가 왜 FT와 다르며, 이 차이 때문에 성능 저하가 발생하고 이를 이를 해결하기 위해 LoRA의 수평적 병렬화를 제안했다면 이 논문은 기존 MTL 시나리오에서 Task별 모듈을 여러개 두는 것에 LoRA를 적용시키고, 이로인한 연산량 증가를 TA, TS로 구분지어서 줄였음. 전형적인 SOTA 찍었으니 왜 이 메소드가 좋은지는 굳이 설명하지 않음 느낌
Summary
Motivation
- 대규모 vision 및 language model은 다양한 downstream task에 적응성이 뛰어나지만, 모든 downstream task마다 전체 parameter를 fine-tuning하는 것은 비효율적
- Task 수가 증가할수록, 특히 computational resource가 제한된 환경에서는 효율성 문제가 심화
- Parameter-Efficient Fine-Tuning (PEFT) 방법들이 등장했으나 대부분 single-task adaptation에 초점
- Multi-Task Learning (MTL) architecture에서의 parameter-efficient 훈련은 아직 충분히 연구되지 않음
- 기존 접근법의 한계:
- Task별로 개별 module을 추가하고 한 번에 하나의 task에 적응시키는 방식
- 각 task마다 별도의 inference 및 training 경로 필요 → task 수에 비례하여 computation cost 증가
- Task 간 knowledge sharing의 이점을 활용하지 못함
- MTL의 주요 과제: 다양한 task requirement 충돌 속에서 단일 shared backbone을 효과적으로 적응시키는 방법
Method
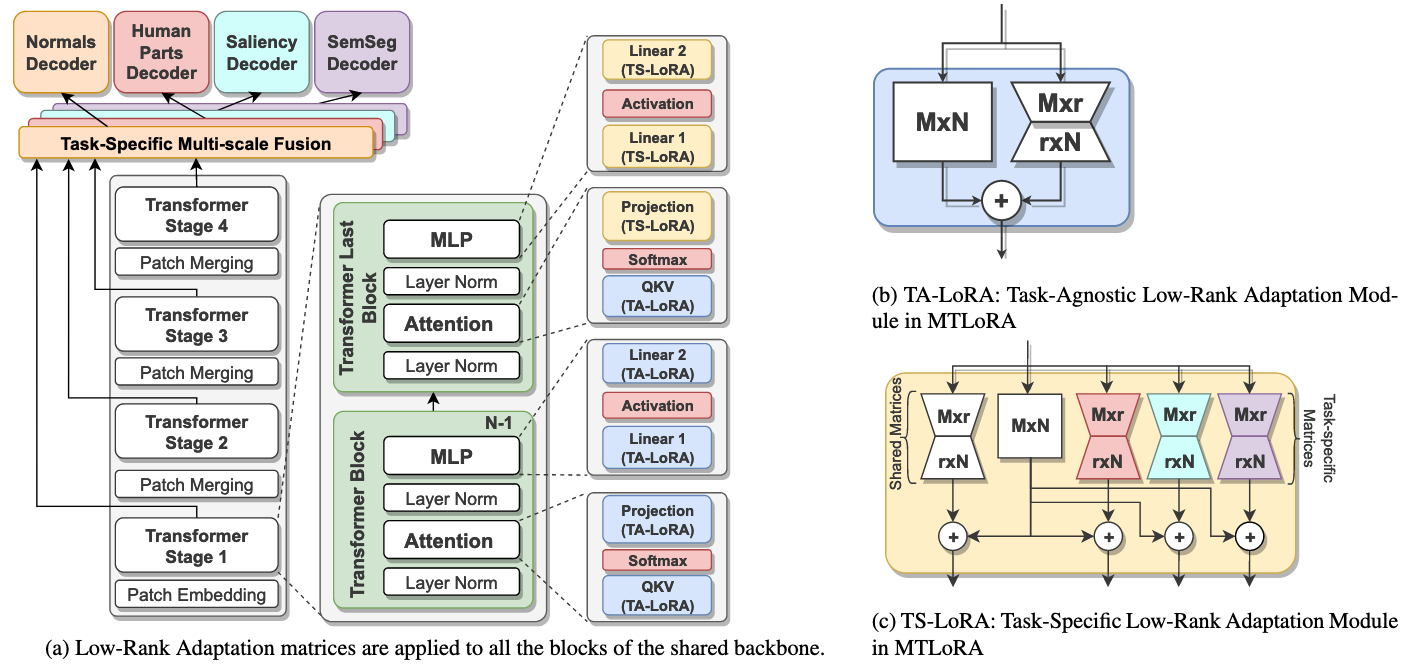
- Low-rank parametrized update matrix 사용:
- 기존:
(전체 parameter 업데이트) - MTLoRA:
(low-rank decomposition 표현)
-, , rank - Training 중
는 고정되고 와 만 learning
- 기존:
- Shared encoder와 Task-specific decoder로 구성 → Shared encoder에 TA/TS-LoRA가 사용됨
- Task-Agnostic Low-Rank Adaptation (TA-LoRA):
- Task 간 shared feature 캡처
- 각 transformer block에 적용 (stage의 마지막 block 제외)
- QKV computation, Projection layer, MLP block에 적용
- Task-Specific Low-Rank Adaptation (TS-LoRA):
- 각 task에 특화된 feature learning
- 각 stage의 마지막 block에 배치
- Task-specific representation 생성 및 task conflict 해결
- 수식:
- Hierarchical vision transformer는 여러 stage에서 다른 scale의 feature 생성
- TS-LoRA module을 통해 각 stage에서 task-specific feature 생성
- Task-specific multi-scale fusion layer를 통해 각 task에 최적화된 feature 통합
- Layer Normalization, Patch Embedding 등 저비용 module도 함께 학습하여 성능 향상
- MTLoRA+: Patch Merging module에 low-rank decomposition 적용하여 parameter 효율성 추가 개선
Method 검증
실험 환경
- PASCAL-Context 데이터셋 사용: semantic segmentation, human part detection, surface normals estimation, saliency distillation task
- Swin Transformer를 backbone으로 사용
- 여러 baseline과 비교:
- Single task baseline
- MTL - Tuning Decoders Only
- MTL - Full Fine-Tuning
- Adapter, Bitfit, VPT, Compactor, LoRA 등 PEFT 방법
MTLoRA vs. Full Fine-tuning MTL
- MTLoRA(r=64)와 full fine-tuning 비교:
- Semantic segmentation: 67.9 mIoU vs. 67.56 mIoU (0.34 상승)
- Human parts: 59.84 mIoU vs. 60.24 mIoU (0.4 감소)
- Saliency: 65.40 mIoU vs. 65.21 mIoU (0.19 상승)
- Normals: 16.60 rmse vs. 16.64 rmse (0.04 감소, 낮을수록 좋음)
- 평균 MTL 정확도(Δm): +2.55% 향상 → full fine-tuning보다 우수한 성능
- Trainable parameter 수: 8.34M vs. 30.06M (3.6배 감소) → parameter 효율성 크게 향상
MTLoRA의 Rank(r) 영향
- r=16: parameter 4.95M, 성능 +1.35%
- r=32: parameter 6.08M, 성능 +2.16%
- r=64: parameter 8.34M, 성능 +2.55%
- Parameter 수와 성능 사이 명확한 trade-off 관계 확인 → 적용 환경에 맞게 유연하게 조정 가능
MTLoRA+의 효율성
- MTLoRA+(r=16): parameter 4.29M, 성능 +1.19%
- 비슷한 parameter 수의 다른 방법(Bitfit, VPT, Compactor 등)보다 우수한 성능
- Patch Merging 등 추가 module에 low-rank decomposition 적용의 효과 입증
Non-Attention Module 영향 분석
- 모든 module을 fine-tuning할 때 최고 성능 달성 (+2.55%)
- Patch Merging을 고정할 경우 가장 큰 성능 하락 (+1.74%) → 이 module의 중요성 입증
- 다양한 module의 기여도 확인 → MTL에서 module별 역할 이해
Low-Rank Decomposition Module 위치에 따른 영향
- QKV computation module이 가장 중요 (제거 시 가장 큰 성능 하락)
- 각 위치의 low-rank decomposition module이 전체 성능에 중요한 기여
- Module별 선택적 적용을 통한 추가 efficiency-performance trade-off 최적화 가능성 제시
대규모 Backbone에서의 확장성
- Swin-Base backbone(ImageNet-22K pre-trained)에서도 효과적
- Single-task fine-tuning 대비 일관된 성능 향상
- 다양한 rank 값(r=8, 16, 32)에서 안정적인 성능 → 방법의 확장성 입증