Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
Although pretrained language models can be fine-tuned to produce state-of-the-art results for a very wide range of language understanding tasks, the dynamics of this process are not well understood, especially in the low data regime. Why can we use relatively vanilla gradient descent algorithms (e.g., without strong regularization) to tune a model with hundreds of millions of parameters on datasets with only hundreds or thousands of labeled examples? In this paper, we argue that analyzing fine-tuning through the lens of intrinsic dimension provides us with empirical and theoretical intuitions to explain this remarkable phenomenon. We empirically show that common pre-trained models have a very low intrinsic dimension; in other words, there exists a low dimension reparameterization that is as effective for fine-tuning as the full parameter space. For example, by optimizing only 200 trainable parameters randomly projected back into the full space, we can tune a RoBERTa model to achieve 90% of the full parameter performance levels on MRPC. Furthermore, we empirically show that pre-training implicitly minimizes intrinsic dimension and, perhaps surprisingly, larger models tend to have lower intrinsic dimension after a fixed number of pre-training updates, at least in part explaining their extreme effectiveness. Lastly, we connect intrinsic dimensionality with low dimensional task representations and compression based generalization bounds to provide intrinsic-dimension-based generalization bounds that are independent of the full parameter count.
Problem:: 수백만 개의 파라미터를 가진 언어 모델이 적은 데이터로도 효과적으로 Fine-tuning되는 현상을 설명하기 어려움 / 기존 접근법으로는 Low Data Regime에서 정규화 없이도 높은 성능을 보이는 이유를 이해하기 어려움
Solution:: Intrinsic Dimensionality라는 개념을 도입하여 언어 모델 Fine-tuning의 효과를 분석 / 모델이 저차원의 Intrinsic Dimensionality에서 최적화 되므로 적은 데이터로도 높은 성능 달성 가능을 보임 / Structure-Aware Intrinsic Dimension(SAID) 방법으로 더 효과적인 측정 방법 제안
Novelty:: 사전학습된 언어 모델이 매우 낮은 Intrinsic Dimension을 가짐을 발견 / 모델 크기가 클수록 Intrinsic Dimension이 감소하는 역상관관계 증명 / Pre-training이 다운스트림 태스크의 압축 프레임워크를 학습한다는 새로운 해석 제시 / 전체 파라미터 수가 아닌 Intrinsic Dimension에 기반한 일반화 경계 제시
Note:: 이 연구는 LoRA와 같은 파라미터 효율적인 Fine-tuning 기법의 이론적 기반 제공
Summary
Motivation
- 사전학습된 언어 모델은 작은 타겟 데이터셋에 Finetuning되어 높은 성능을 보이나, 그 과정의 동작 원리는 충분히 이해되지 않음
- 핵심 질문: 어떻게 수억 개의 파라미터를 가진 모델이 수백 또는 수천 개의 Labeled Examples만으로 효과적으로 Finetuning될 수 있는가?
- 기존 접근법으로는 특히 Low Data Regime에서 정규화 없이 Finetuning이 성공하는 이유를 설명하기 어려움
- 저자들은 "Intrinsic Dimensionality"이라는 새로운 렌즈를 통해 Finetuning 과정을 분석하는 방법 제안
Method
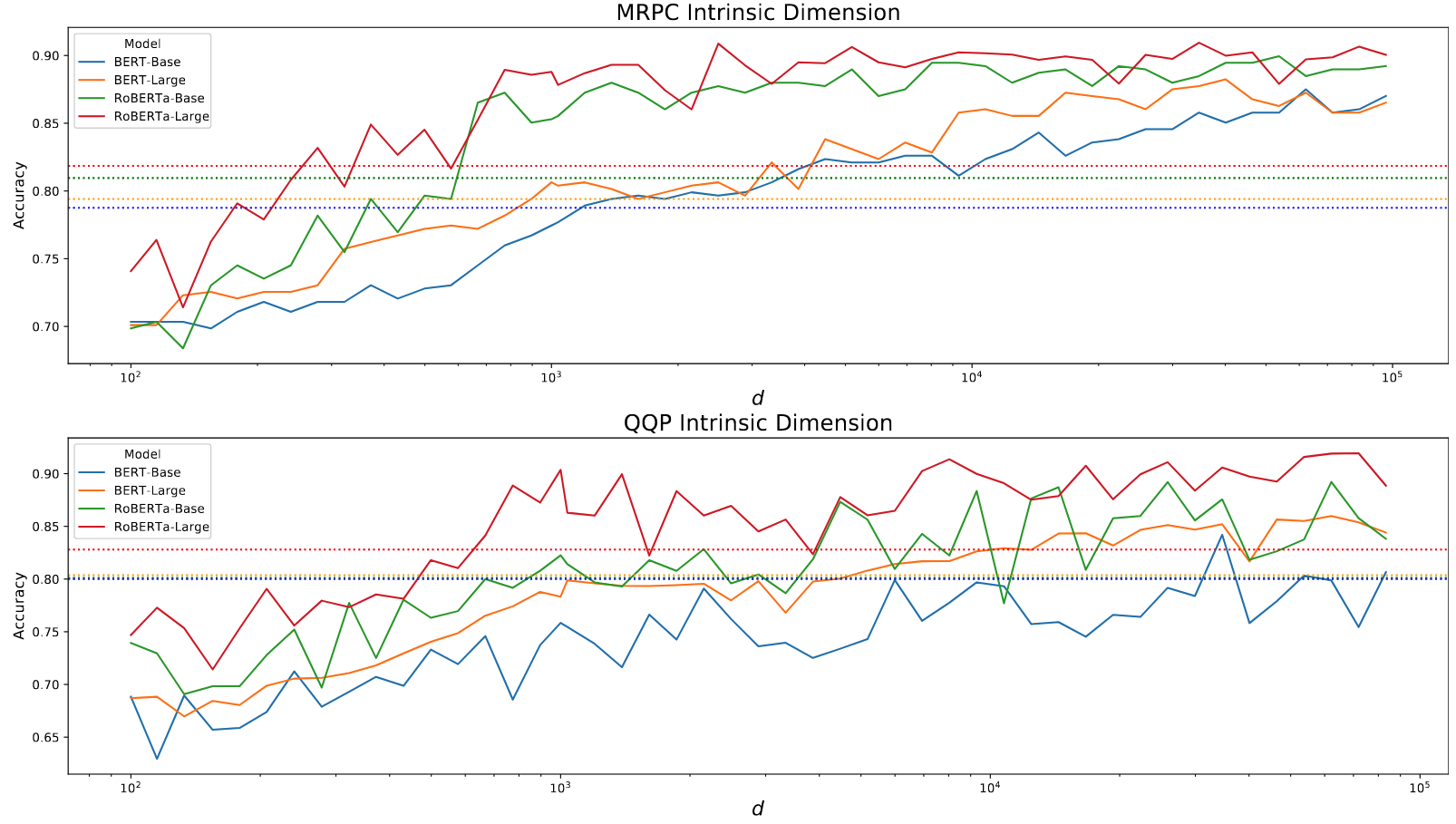
점선이 각 모델을 Full Finetuning 했을 때의 90% 성능. 90%를 달성하기 위해 학습해야하는 파라미터 수가 많지 않음을 볼 수 있음
- Intrinsic Dimensionality: 목적 함수를 특정 Precision Level까지 최적화하는 데 필요한 최소한의 차원
- 사전학습된 언어 모델에서 Intrinsic Dimension을 측정하면 각 End Task에 Finetuning하는 데 필요한 Free Parameters의 수를 알 수 있음
- 측정 방법: 파라미터 공간에서 Random Linear Projection을 사용해 저차원 Subspace를 찾고 그곳에서 최적화 수행
(여기서 는 저차원에서 고차원으로의 투영) - Fastfood Transform을 주로 활용:
, - Fastfood Transform은 고차원 데이터의 계산 비용을 크게 줄이는 효율적인 행렬 연산 방법
는 Hadamard 행렬, 는 독립적인 Standard Normal Entries를 가진 Random Diagonal 행렬, 는 Equal Probability ±1을 가진 Random Diagonal 행렬, 는 Random Permutation 행렬 - Hadamard 행렬과의 곱셈은 Fast Walsh-Hadamard Transform을 통해
복잡도로 계산 가능 - 이 방식은 수억 개의 파라미터를 가진 대형 언어 모델에서도 계산 가능한 유일한 방법
- Structure-Aware Intrinsic Dimension(SAID): Transformer 모델의 Layer-wise Structure를 고려한 개선된 측정 방법
- Transformer 모델에서 각 레이어가 서로 다른 기능을 담당하고 개별적으로 Specialize Separately한다는 기존 연구 결과에 기반
개의 레이어에 대해 각 레이어별로 중요도에 따른 Scaling Coefficient 를 도입 - 저차원 파라미터
중 일부를 Layer-wise Scaling에 할당하여 특정 레이어가 Task Relevant Information을 더 많이 처리할 수 있도록 함 - 이를 통해 기존 레이어 구조를 무시하는 Direct Intrinsic Dimension(DID) 방법보다 더 효과적인 Intrinsic Dimension 측정 가능
Method 검증
Sentence Prediction Tasks의 Intrinsic Dimension 측정
- MRPC와 QQP 데이터셋에서 4개 모델(BERT-Base, BERT-Large, RoBERTa-Base, RoBERTa-Large)의 Intrinsic Dimension 측정
- RoBERTa-Large는 MRPC에서 단 200개 파라미터만으로 전체 성능의 90% 달성 → 일반적인 NLP 태스크의 Intrinsic Dimension이 기존 가정보다 훨씬 낮음을 입증
- 모델 크기가 더 큰 RoBERTa가 BERT보다 더 낮은 Intrinsic Dimension 보임 → 파라미터 수와 Intrinsic Dimension 간의 Inverse Correlation 시사
- SAID 방법이 DID 방법보다 일관되게 더 나은 성능을 보임 → 레이어 구조를 고려한 접근법의 효과성 입증
Pretraining과 Intrinsic Dimension의 관계
- RoBERTa-Base를 처음부터 학습시키며 6개 NLP 태스크에서 Intrinsic Dimension 변화 관찰
- Pretraining이 진행될수록 Intrinsic Dimension이 지속적으로 감소 → Pretraining이 암묵적으로 다운스트림 태스크의 Intrinsic Dimension을 최소화함
- 해결하기 쉬운 태스크(Yelp Polarity 등)일수록 일관되게 낮은 Intrinsic Dimension 보임 → 태스크 복잡성과 Intrinsic Dimension 간 상관관계 존재
- 이는 Pretraining이 NLP 태스크의 "Compression Framework"를 학습하는 과정으로 해석 가능
Parameter Count와 Intrinsic Dimension의 관계
- 다양한 pre-trained 모델(BERT, RoBERTa, BART, Electra, Albert, XLNet, T5, XLM-R)을 분석
- 파라미터 수가 증가할수록 Intrinsic Dimension이 감소하는 강한 경향성 발견 → 대형 모델의 효과성을 설명하는 새로운 관점 제공
- 같은 파라미터 수 범위에서는 Pretraining Methodology가 Intrinsic Dimension에 중요한 영향을 미침
- 특히 10^8 파라미터 범위에서 RoBERTa 방식의 Pretraining이 다른 방법보다 우수함
Intrinsic Dimension과 일반화 성능의 관계
- 사전학습 체크포인트별 Intrinsic Dimension과 평가 정확도의 상관관계 분석
- 낮은 Intrinsic Dimension이 더 높은 평가 정확도와 강한 상관관계 보임 → Intrinsic Dimension이 일반화 성능의 지표가 될 수 있음
- 상대적 일반화 간극(훈련-평가 성능 차이)도 Intrinsic Dimension이 낮을수록 감소 → 복잡성 측정으로서의 Intrinsic Dimension 유효성 입증
- 그래프에서 모든 태스크에서 일관된 패턴 관찰: Intrinsic Dimension이 감소함에 따라 평가 정확도는 증가하고 일반화 간극은 감소
이론적 일반화 경계 분석
- Compression-based Generalization Bounds를 Intrinsic Dimension 프레임워크에 적용
→ 일반화 경계가 전체 파라미터 수가 아닌 Intrinsic Dimension에 의존함 - 이는 대형 모델의 우수한 일반화 성능을 이론적으로 뒷받침
- 모델의 일반화 능력은 모델의 복잡성이 아닌, 다운스트림 태스크를 압축하는 능력에 의해 결정됨을 시사